
Language Model Research
- Recent language model research focuses on continual feeding to minimize loss.
- Technical details of large language models are discussed, including common adaptations to the Transformer architecture.
- DeepSpeed is the preferred library for training large language models, with important optimization methods coming from the paper "ZeRO: Memory Optimizations for Large-Scale Language Models".
- Long context training has improved significantly, allowing models to understand very long sequences.
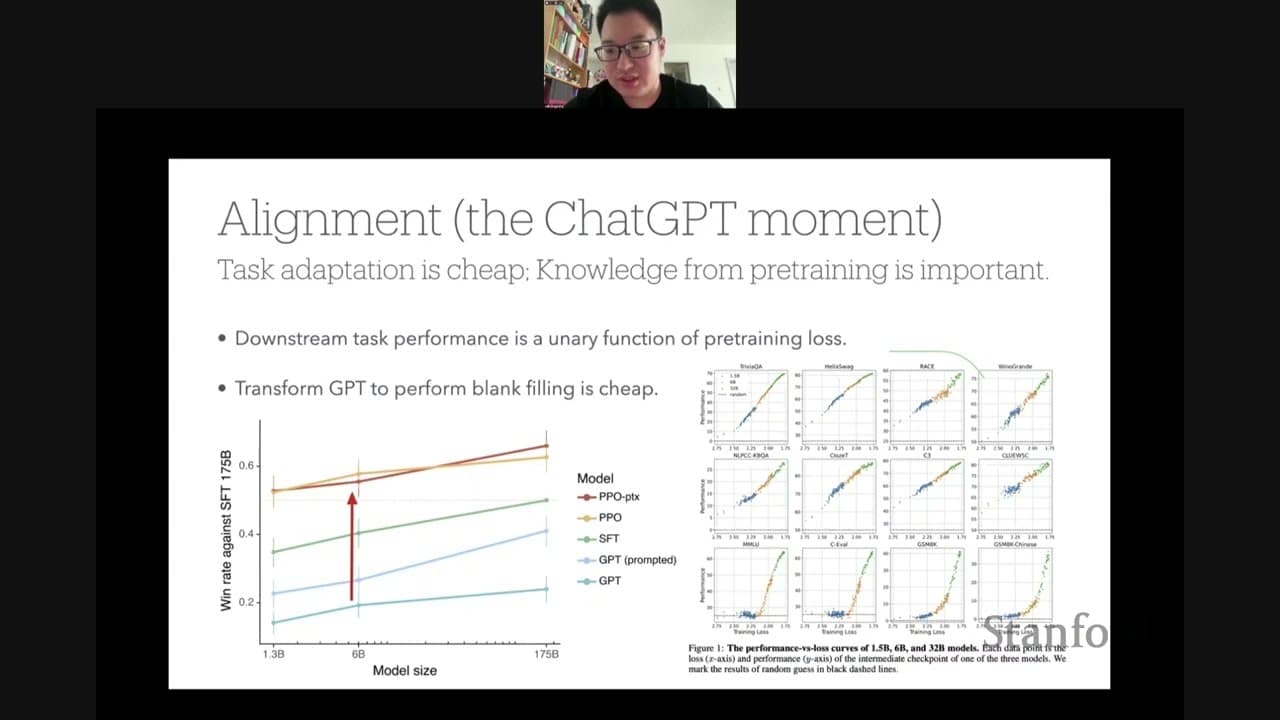
- Alignment methods such as SFT and IRF are used to improve the performance of language models.
- Data cleaning, filtering, and sizing are crucial for the success of large language models.
Multimodal Models
- CLIP is a model that bridges the gap between images and text by extracting important features from images and aligning them with text features.
- CoM is a model that adds image understanding ability to language models while preserving their language behavior.
- High-resolution cross-attention models are used for web agents that take screenshots as input and perform various tasks.
- WeLM is a language model that uses a simple adaptation of LoRA to support high-resolution inputs while maintaining efficient computation.
- Autoregressive image generation models like C-VQVAE and Parti can generate images from text or text from images, but they are slower and perform worse than diffusion models.
- Diffusion models, such as the Rel diffusion model, are currently the dominant approach for image generation due to their faster sampling and better performance.
- Recent advancements in diffusion models, such as SoR, have shown improvements in video generation by eliminating flickering and generating high-quality images.
Future Research Directions
- Video understanding will become increasingly important due to the abundance of videos and the limitations of current models.
- Embodied AI will become more important in research and closely related to multimodality research.
- Speech AI is an underestimated field with significant user need and application potential, but it lacks sufficient GPU resources and researchers.
- New architectures for self-supervised learning and optimizers, as well as ways to transform compute to high-quality data, are important areas for future research.
Key Insights
- The focus of the AI community has shifted towards improving data rather than solely relying on architecture or algorithms.
- High-quality data is more important than the architecture of models for many tasks.
- Autoregressive models are slower in image generation compared to diffusion models due to token-by-token prediction.
- Diffusion models have an advantage in modeling the relationship between different parts of an image.






