
Motivation for Heterogeneous Computer Architecture
- Heterogeneity in computer architecture is motivated by the desire to exploit different program characteristics, with a key focus on data parallel computation for energy efficiency and high performance. 22s
- Energy efficiency is crucial in modern computing due to the end of Dennard scaling, where increasing transistors leads to higher power dissipation, making specialization essential for reducing overhead and improving energy use. 1m46s
Inefficiency of CPUs
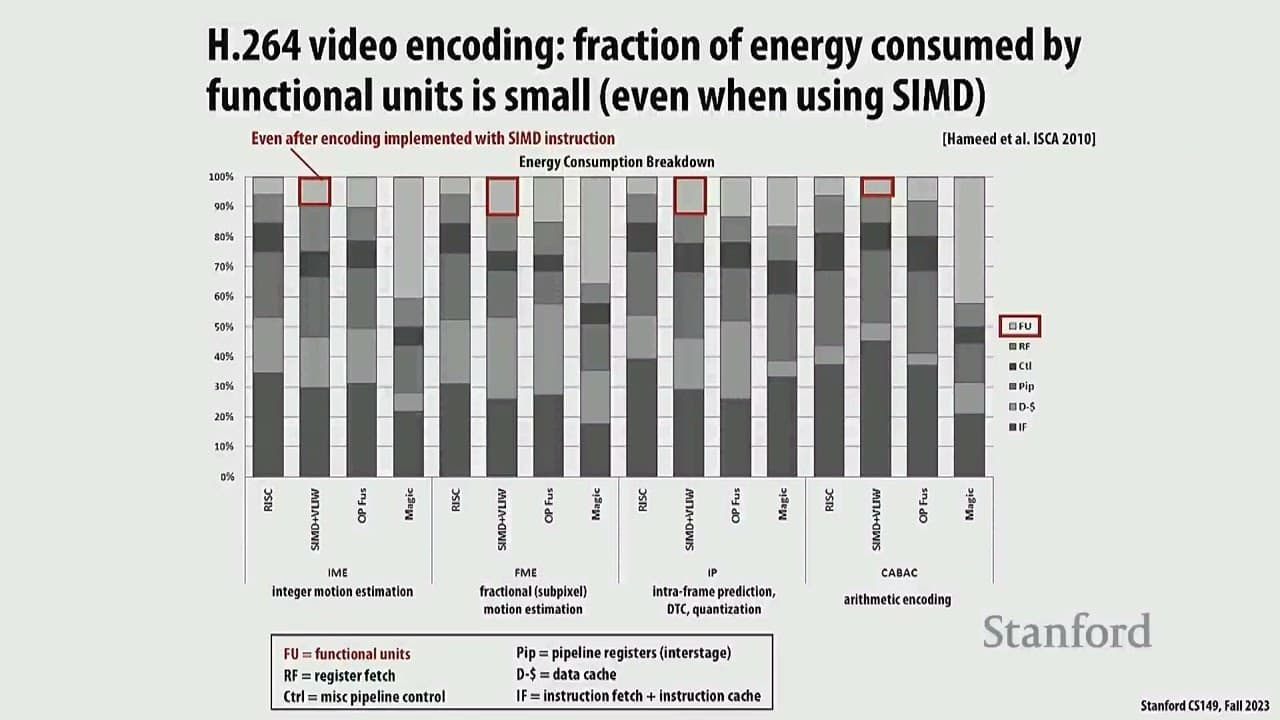
- CPUs are fundamentally inefficient because a large portion of energy consumption is dedicated to instruction handling, data movement, and control overhead, rather than the actual computation itself. 6m12s
- SIMD instructions improve efficiency by performing operations on multiple data elements simultaneously, amortizing the non-computational overhead across more data operations. 7m52s
Trade-offs in Hardware Options
- While wider SIMD units offer higher peak performance, they may not always be fully utilized, leading to lower average performance if there's insufficient data parallelism. 8m31s
- Specialized hardware, like ASICs designed for specific algorithms such as FFT, can significantly outperform general-purpose CPUs in terms of energy efficiency and silicon area usage, but at the cost of flexibility and programmability. 10m20s
- There is a range of hardware options available to programmers, each with its own trade-offs in terms of energy efficiency and the programming effort required. Simpler CPUs are easier to program but less energy efficient, while ASICs offer the highest energy efficiency but demand specialized hardware design expertise. 22m37s
Specialized Accelerators
- Molecular Dynamics is an important area of chemistry for which specialized accelerators, such as Anton, have been developed to improve performance over CPUs and GPUs. 14m10s
- The Tensor Processing Unit (TPU) from Google is an accelerator that significantly speeds up dense matrix multiplication, a key operation in machine learning. 15m36s
- Field Programmable Gate Arrays (FPGAs) offer a middle ground between fixed-function hardware and general-purpose processors by providing configurable logic blocks, dedicated functions (like dense memory and multipliers), and the flexibility to adapt to evolving algorithms. 17m25s
- GPUs, initially designed for general-purpose thread processing, are evolving to incorporate specialized units like tensor cores for improved performance in areas like machine learning. However, programming these specialized units effectively can be challenging. 23m41s
Challenges of High-Level Synthesis
- While high-level synthesis offers the promise of generating hardware from C code, it faces challenges. C programs are not inherently designed for hardware description, leading to ambiguity in hardware implementation. Additionally, the use of pragmas to guide the compiler often necessitates a deep understanding of hardware, undermining the goal of high-level abstraction. 26m53s
Spatial Programming Language
- Spatial is a high-level programming language designed for hardware accelerator design, enabling performance-oriented programmers to specify hardware. 27m58s
- Spatial allows programmers to express parallel patterns, including data parallel patterns like map, zip, and reduce, using independent and dependent parallelism, as well as manage locality by explicitly specifying the memory hierarchy. 28m57s
- Unlike CPUs, where data movement between memory and cache is handled automatically, Spatial requires programmers to explicitly move data between different levels of the memory hierarchy, such as from DRAM to SRAM. 34m32s
- The spatial language is embedded in the Scala programming language. 36m5s
Programming with Spatial
- When programming an accelerator with spatial, the user must define data structures within the accelerator to hold data that is moved from DRAM. 41m18s
- To make efficient use of the interface between DRAM and an accelerator, it is best to fetch a tile of data instead of single elements. 42m32s
- The reduction process can be parallelized by performing multiple steps concurrently for different parts of the data, similar to pipelining. 45m2s
- Step two of the algorithm, which involves performing the same operation on all elements within a tile, can be efficiently parallelized using SIMD (Single Instruction, Multiple Data). 46m22s
- Pipelining in hardware can improve performance but requires additional memory for double buffering. 49m31s
- Spatial programmers are responsible for expressing algorithms, managing memory hierarchies, specifying parallelism, and determining tiling factors. 50m37s
Streaming Execution Models
- Fused attention, as used in models like Flash Attention, offers benefits such as avoiding full matrix materialization and minimizing memory bandwidth. 52m57s
- Streaming execution models avoid materializing matrices by using a pipeline execution model where data moves through FIFOs (first-in, first-out buffers) between kernels. 57m34s
- Spatial semantics allow for concurrent execution of for loops, enabling a producer-consumer relationship between kernels connected by FIFOs. 58m34s
- Flash attention optimizes streaming further by using a running sum and scaling, reducing the required FIFO size for computations like row operations. 1h3m16s
- Streaming execution models allow for the pipelining of computations for different output tiles, providing an extra dimension of parallelism and performance. 1h5m9s
- Streaming execution models offer the benefit of automatic kernel fusion through techniques like double buffering or FIFOs, potentially eliminating the need to explicitly create fused kernels. 1h5m21s
Spatial as a Design Space Exploration Tool
- Spatial, as a programming model and design space exploration tool, helps in understanding application bottlenecks, such as memory or compute bounds, and making trade-offs in hardware resource allocation and memory hierarchy design for accelerators. 1h10m51s
Upcoming Discussion
- There is a possibility that Kon will discuss the design of memory on Thursday. 1h11m29s
Conclusion
- The discussion on acceleration and heterogeneous compute has concluded. 1h11m37s






