
Open Healthcare Network and CodePilot
- Open Healthcare Network is an open-source project that connects hospitals with care centers and helps track patient journeys. 00:01:38
- The project, built with contributions from over 400 people worldwide, aims to address the shortage of healthcare professionals in India. 2m38s
- CodePilot has significantly improved the quality of code in the project, acting as a personal assistant for developers. 2m52s
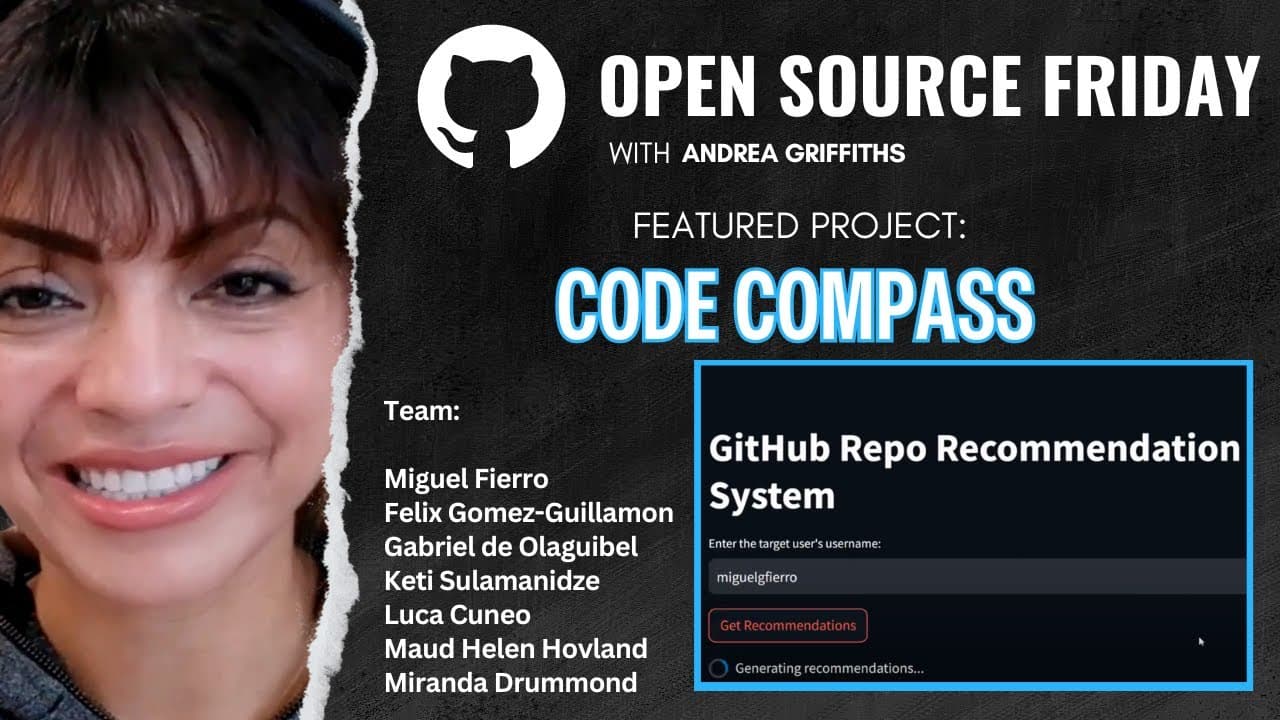
CodeCompass: Functionality and Features
- CodeCompass can generate recommendations for new users in about a minute. It also takes about a minute for the Streamlit app to load all of the data. 14m19s
- The chatbot component of CodeCompass allows users to interact with repositories, extract file structures, get file contents, view branches and commit histories, and search repositories and commits by keywords. 15m15s
- The chatbot can provide summaries of code within specific files, even if the user is unfamiliar with the programming language. 00:16:59
- CodeCompass is a tool that facilitates personalized recommendations to improve the developer experience, especially for those new to open source and overwhelmed by the vastness of platforms like GitHub. 47m0s
CodeCompass Development Team
- Gabriel Deel is a student at IE University of Madrid and worked as a project manager and data engineer on the CodeCompass project. 8m42s
- M. Helen Hofland is a Norwegian student at IE University who worked as a data engineer on the project. 9m17s
- Luca, a Peruvian student at IE University, contributed to the data engineering team and assumed a project lead role, focusing on code quality and documentation. 9m41s
- Ky Soloman, from Georgia, worked as a data scientist and MLOps engineer on the project. 10m17s
- Miranda Germond, of English and Italian descent, took on multiple roles including data scientist, MLOps, and data engineering. 10m49s
CodeCompass: Dataset and Data Management
- The project uses a large dataset of GitHub information, larger than a comparable dataset found on Kaggle. 22m6s
- The dataset was created by querying the GitHub API for users with at least 1,000 followers and 10 repositories. 22m35s
- The data collected includes user information, repositories, and repositories they have starred, with a limit of 10 repositories per user. 23m36s
- The project initially used Google Cloud to store and manage CSV files containing generated data. However, as the data grew, uploading and downloading these files became problematic. 25m21s
- To address the data management challenges, the team explored using Redis. A branch named "redis 2" was created to implement a primary database in Redis. 25m43s
CodeCompass: Technology and Algorithms
- The team considered using long and short-term user representation (LST) as an alternative algorithm. However, due to the lack of time-stamped user interaction data, this option was deemed unsuitable for the time being. 30m16s
- The developers chose to use CSV files instead of JSON files because they found them easier to work with for the initial implementation of the project. 32m10s
- The developers used GPT 3.5 and GPT 4 for their project, but they found that GPT 3.5 did not provide the level of depth and detail they were looking for. 33m22s
- The developers implemented Llama 3, an open-source language model, as part of their project. 34m32s
- The CodeCompass system uses OpenAI's assistance API, specifically the GPT-4 model, to process user queries and interact with the GitHub API. 36m17s
- The system can handle both general knowledge questions and requests related to specific GitHub repositories, such as retrieving repository structure or content. 37m0s
CodeCompass: Future Improvements
- Future improvements include integrating open-source language models like Gemini and Langchain, allowing users to choose between different models, and hosting the system with a robust database like M's database for wider accessibility and feature implementation. 39m0s
- Potential improvements to the project include hosting it and implementing a pipeline for continuous data scraping and comparison. This pipeline would track user numbers, repository presence in the database, and facilitate model fine-tuning. 41m32s
- To enhance data loading and generation, there are plans to explore in-memory and open-source databases like Redis. This would involve directly querying the database and potentially using Redis Enterprise for enhanced value and recommendation speed. 42m32s
- Future improvements also encompass adding compatibility for private repositories and exploring integration with platforms beyond GitHub to create a cross-platform recommender. 43m0s
Contributing to CodeCompass
- It is recommended to open an issue to discuss potential improvements with the team before submitting a pull request. 46m20s
Project Feedback and Recognition
- Miguel, who guided the project, believes that CodeCompass is impactful enough to be integrated into a real organization and encourages the creators to connect with GitHub for potential integration. 50m26s
- CodeCompass is a fantastic project, and the team behind it should be proud of their accomplishment in such a short time. 57m58s
Advice for Aspiring Developers
- Gabriel's advice for learning is to build something useful, even if it's just for personal use. 54m30s
- Kitty emphasizes the importance of starting from scratch and iteratively building upon the project, prioritizing progress over perfection. 55m9s
- Miranda encourages embracing failure as a learning opportunity and seeking help when needed. 55m33s
- Luca suggests starting with a small project and gradually scaling it up, incorporating testing and modularity along the way. 56m12s
- Mod advises not to be afraid of being a beginner, as everyone starts somewhere, and emphasizes the importance of trying. 56m44s
- People should try new things in the tech industry, even if they consider themselves advanced, as there is always something new to learn. 57m30s
GitHub Universe
- GitHub Universe is happening again this year in San Francisco in October. 1h1m53s